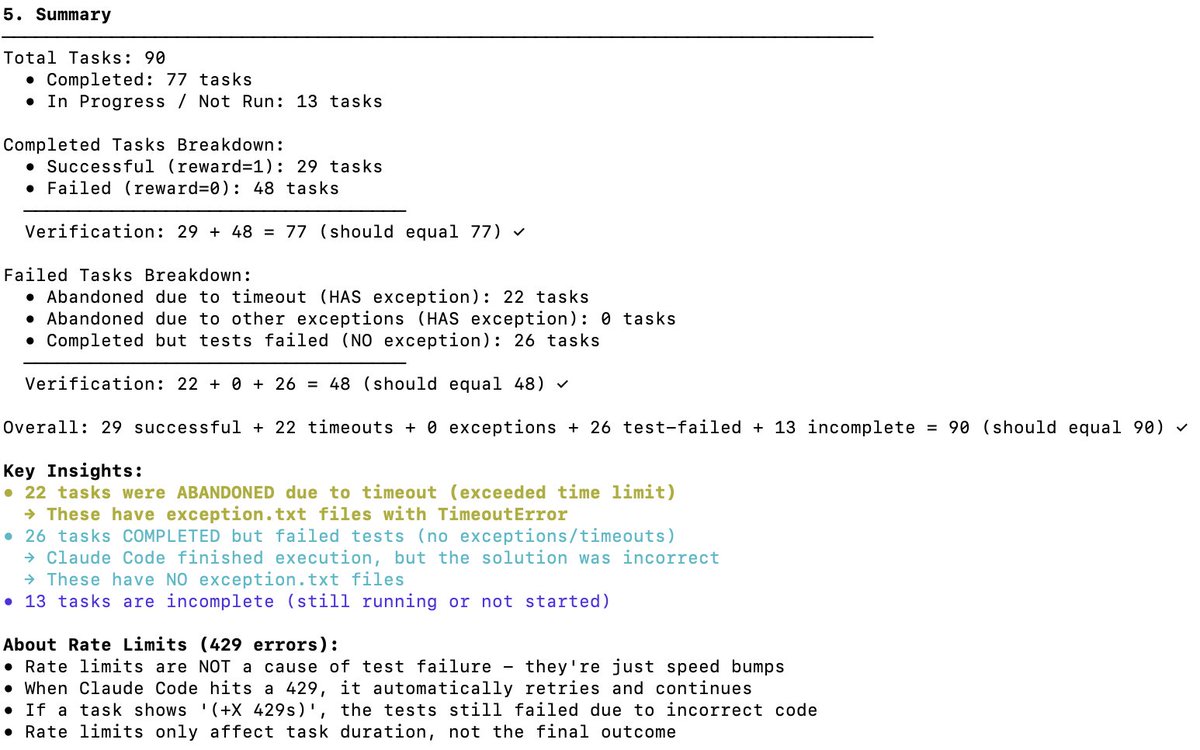
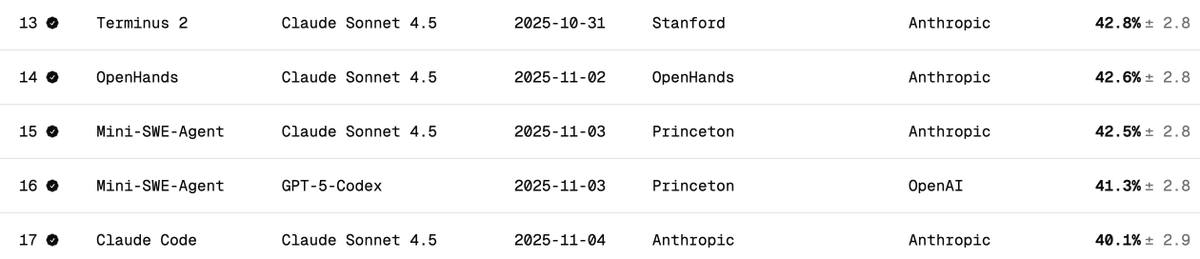
Verificación independiente del rendimiento de Terminal Bench 2 de DeepSeek V3.2 El Terminal Bench mide cómo un modelo soporta/ejecuta un agente en un escenario de terminal (p. ej., Claude Code, Codex CLI, Gemini CLI). En mi opinión, este es el benchmark LLM más importante para el desarrollo de software de IA. Implica que la IA opere tu CLI para descargar software, desarrollar código, realizar pruebas, etc. ¿Cual es la puntuación oficial? La puntuación oficial de DeepSeek v3.2 es de 46,4 (pensamiento) y 37,1 (no pensamiento), como se indica en la tabla a continuación. Se utilizó el arnés Claude Code, como se indica en el artículo. ¿Cómo se comporta Claude Code + Sonnet 4.5 en este benchmark? A continuación se muestran las puntuaciones de referencia de Claude Sonnet 4.5 en diferentes arneses. Cabe destacar que la puntuación es de alrededor del 40 % para el arnes Claude Code. ¿Qué puntuaciones obtuve para DeepSeek V3.2 con Claude Code Harness? Hice pruebas con DeepSeek-Reasoner (Thinking). De casi 90, se ejecutaron 77 pruebas antes de que Harbor (orquestador) dejara de funcionar. 77 es un buen número para hacerse una idea, suponiendo que se trate de muestras imparciales. - 29 - Tuvo éxito - 48 - Falló (22 tiempos de espera + 26 códigos incorrectos generados) Esto sitúa la puntuación en el 38% (bastante impresionante, y ya cerca de Claude Code + Sonnet 4.5 con el 40%). Pero lo que es seguro es que si se le da más tiempo al modelo DeepSeek v3.2, sin duda podrá completar más tareas con tiempo de espera, y su tasa superaría con creces el 38 %; creo que podría alcanzar el 50 %. Sin embargo, entonces la comparación dejará de ser comparable (los creadores de la prueba recomiendan no cambiar la configuración del tiempo de espera). Comparación con otros modelos OSS: A continuación se muestra el uso del arnés Terminus 2. 1. Kimi K2 Pensando - 35,7% 2. MiniMax M2 - 30% 3. Codificador Qwen 3 480B - 23,9% Conclusión: El rendimiento es SOTA para un modelo OSS, y es increíble que casi iguale a Claude 4.5, sin embargo, mi puntuación fue menor que la del equipo DeepSeek: 46.4 (nuevamente, las últimas 13 pruebas no se ejecutaron). Sospecho que podrían haber modificado el comportamiento del código de Claude. Este código activa el modelo de maneras específicas (por ejemplo, mediante ) con las que DeepSeek v3.2 podría no estar familiarizado o no gestionarlo tan bien. Fue genial saber que DeepSeek tiene un punto final de API antrópica; facilitó las pruebas con Claude Code. Solo tengo que colocar settings.json en Docker. DeepSeek (@deepseek_ai) debería compartir de forma transparente cómo lograron esos puntajes. Costo y aciertos de caché: Esta es la parte más increíble. Me costó solo 6 $ ejecutar las 77 pruebas (Harbor abandonó las últimas 13 por alguna razón). Se procesaron cerca de 120 millones de tokens, pero como la mayoría eran de entrada y posteriormente tuvieron aciertos de caché (DeepSeek implementa automáticamente el almacenamiento en caché basado en disco), los costos fueron bastante bajos. Solicitudes al equipo de Terminal Bench: Por favor, faciliten la reanudación de trabajos finalizados antes de completar todas las tareas. Gracias por esta excelente referencia. @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai