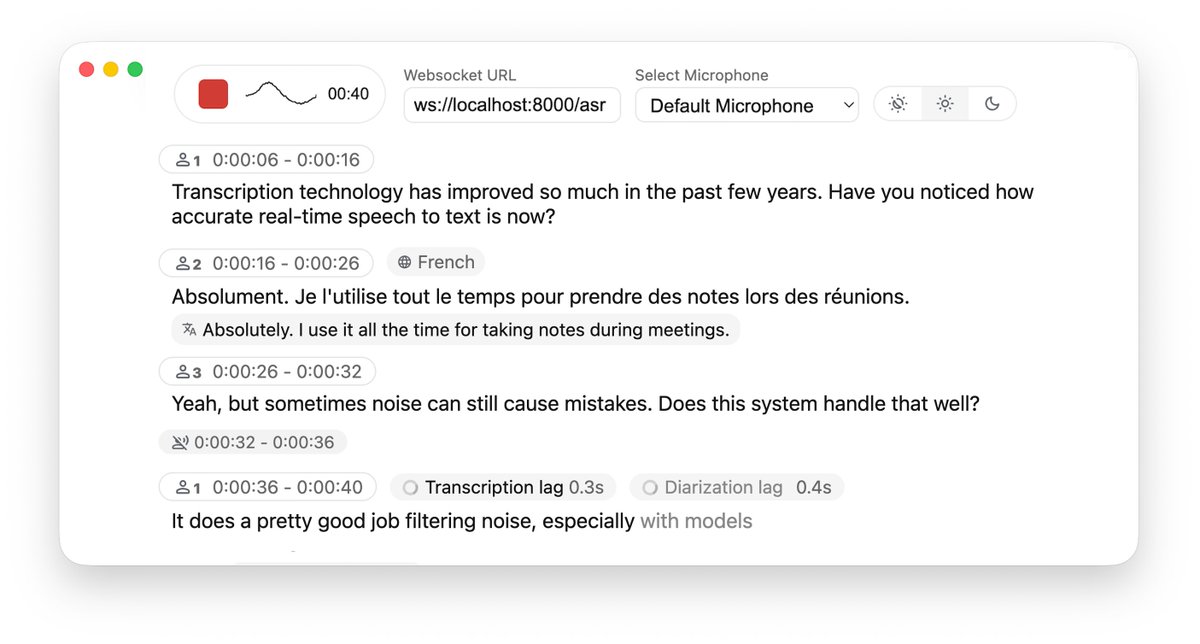
Para lograr la conversión de voz a texto en tiempo real en un proyecto, generalmente hay que elegir una API en la nube, lo que no solo es costoso sino que también genera preocupaciones sobre la privacidad de los datos. Si bien la implementación local de Whisper es gratuita, la experiencia de latencia y segmentación de oraciones al procesar audio en tiempo real suele ser insatisfactoria. Me topé con el proyecto de código abierto WhisperLiveKit en GitHub, que proporciona una solución completa de reconocimiento y traducción de voz local en tiempo real, específicamente optimizada para problemas de latencia de transmisión. No solo admite la transcripción en tiempo real de alta precisión, sino que también tiene reconocimiento de hablante integrado (Diarización) y detección de actividad del habla (VAD), que puede distinguir con precisión quién está hablando y cuándo hace una pausa. GitHub: https://t.co/SVCcyqdqhG El backend es extremadamente flexible y admite la integración con Faster Whisper o el motor mlx-whisper optimizado para Apple Silicon, e incluso integra el modelo NLLW para lograr la traducción en tiempo real de 200 idiomas. El proyecto incluye ejemplos de Python listos para usar, tanto para el servidor como para la interfaz web, compatibles con la implementación en Docker. Proporciona una infraestructura muy sólida para construir un sistema de grabación de reuniones o interpretación simultánea de baja latencia y que preserva la privacidad.