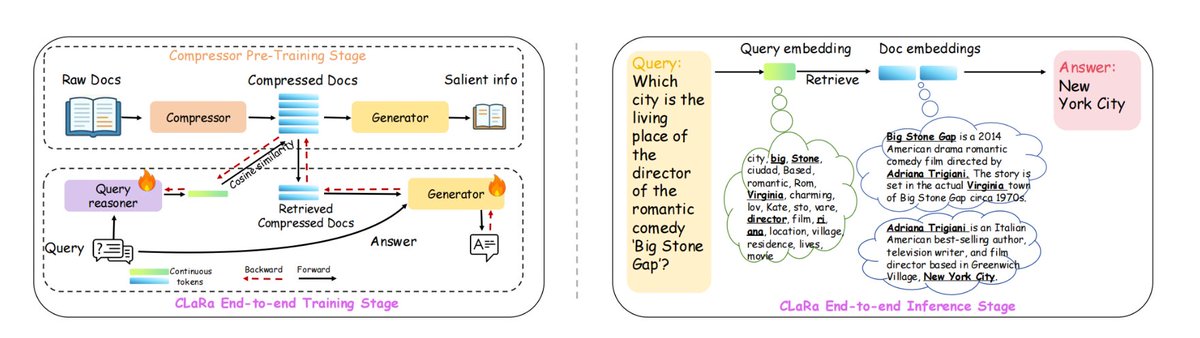
Apple ha desarrollado un nuevo marco RAG llamado ml-clara, que aborda las ineficiencias en el manejo de contextos largos y la separación de los procesos de optimización de generación y recuperación. La idea central es evitar introducir todo el texto en un modelo grande, sino comprimir los procesos de "recuperación" y "generación" en el mismo espacio vectorial continuo diferenciable, lo que permite un entrenamiento unificado y una inferencia de una sola etapa. Esto aborda las siguientes cuestiones: 1) la longitud creciente del contexto que conduce a una explosión en el costo computacional; 2) la inconsistencia en los objetivos de optimización causada por el entrenamiento independiente de la recuperación y los generadores; y 3) el problema de la desconexión del gradiente. En NQ, HotpotQA, MuSiQue y 2Wiki, mantuvo su posición líder en diferentes relaciones de compresión de 4×/16×/32×, e incluso con una compresión de 32×, todavía era superior a la línea base de búsqueda pura sin comprimir. La longitud del contexto se puede comprimir hasta 32×–64× conservando la información esencial necesaria para generar una respuesta precisa. En concreto, 1. En primer lugar, comprimir el preentrenamiento, comprimiendo los documentos en vectores de 32 a 256 dimensiones mientras se preserva la semántica de control de calidad/repetición. 2. Luego, ajuste las instrucciones para adaptar el vector comprimido a la tarea de preguntas y respuestas posterior. 3. Mayor entrenamiento conjunto de extremo a extremo, optimizando tanto la recuperación como los generadores. #RAG #mlclara
github:github.com/apple/ml-clara