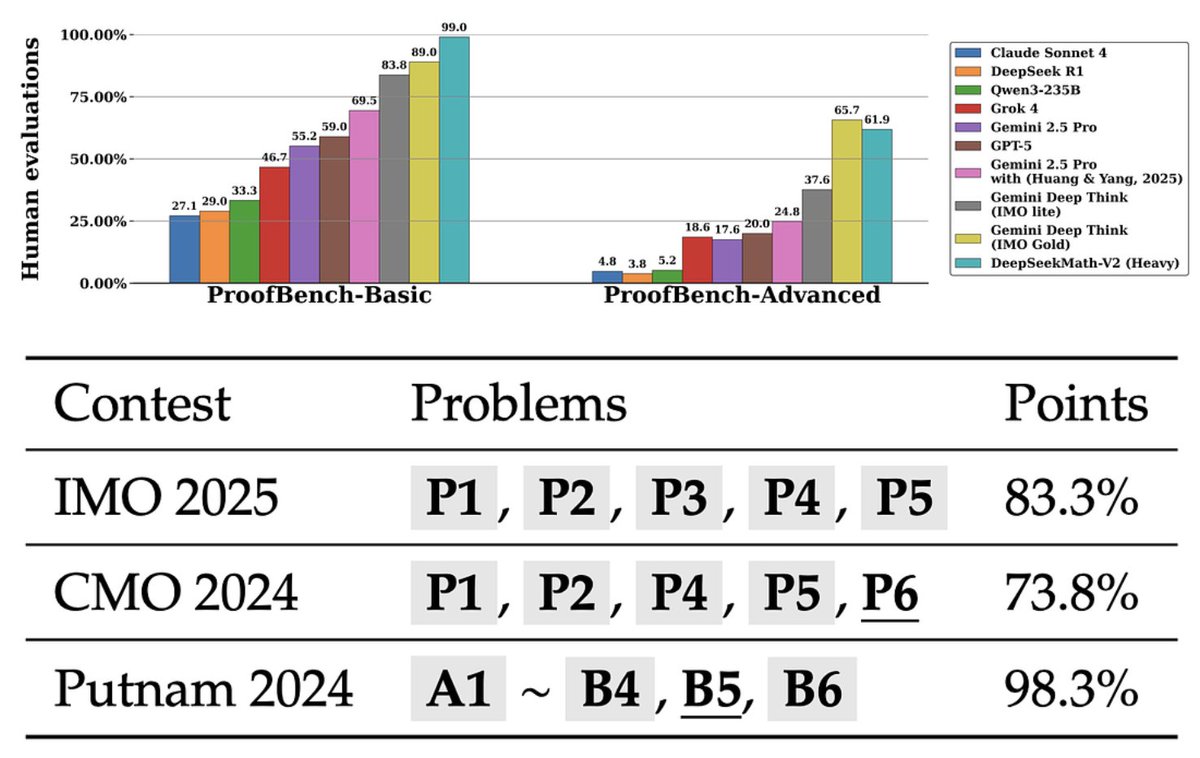
DeepSeek ha publicado en código abierto un gran modelo de razonamiento matemático: DeepSeek-Math-V2. Superando a Gemini para ganar la medalla de oro de la OMI No sólo puede proporcionar la respuesta correcta, sino también verificar si su razonamiento es razonable. La innovación principal es el desarrollo de un sistema de autoverificación que integra generación, verificación y revisión. Capacidades del modelo: Generar automáticamente pruebas matemáticas; Comprueba por ti mismo si cada paso es razonable; La prueba final se emitirá después de que se corrijan los errores de razonamiento. DeepSeek-Math-V2 funciona excelentemente en varias pruebas de matemáticas desafiantes. En las cinco áreas principales de las matemáticas (álgebra, geometría, teoría de números, combinatoria y desigualdades): DeepSeekMath-V2 supera completamente a GPT-5-Thinking y Gemini 2.5 Pro. Rendimiento en competición OMI 2025 (Olimpiada Internacional de Matemáticas): Resolvió 5 de 6 problemas, nivel de medalla de oro. CMO 2024 (Olimpiada Matemática de China): resolvió 4 problemas + 1 puntaje parcial, nivel de medalla de oro. Putnam 2024 (Competencia Americana de Matemáticas Universitarias): 118/120 puntos, casi una puntuación perfecta.
Características de la habilidad Alta precisión: la tasa de respuestas correctas supera la de las series GPT-5 y Gexiaohu.ai/c/a066c4/deeps…uroso: Cada paso de la lógica se autocomprueba para evitar saltos o ilusiones; Fuerte capacidad de superación personal: capaz de mejorar continuamente la calidad de la prueba a través de múltiples rondas de verificación; Buena interpretabilidad: el resultado incluye no sólo la conclusión sino también el proceso de razonamiento completo; Introducción detallada: https://t.co/97LnWmuHox

GitHub:github.com/deepseek-ai/De…9 Deshuggingface.co/deepseek-ai/De…://t.co/2hjUOqj09b