Imaginemos un equipo de software trabajando en un proyecto grande, pero con una regla peculiar: cada ingeniero solo puede trabajar unas pocas decenas de minutos, como máximo unas pocas horas, y luego hay que reemplazar a un nuevo ingeniero. Por lo tanto, este equipo es adecuado para tareas sencillas, pero para proyectos más complejos que requieren tiempos de ejecución largos, como clonar un archivo claude.ai, simplemente no pueden hacerlo. Este es básicamente el estado actual de los agentes de codificación: carecen de memoria y tienen una ventana de contexto limitada. Por lo tanto, no son adecuados para ejecutar tareas de larga duración. La publicación del blog de Anthropic, "Arneses efectivos para agentes de larga duración", analiza específicamente cómo permitir que los agentes sigan realizando tareas en múltiples ventanas de contexto. Primero, veamos los principales problemas que encuentra el Agente en tareas largas. Hay tres tipos principales: El primer tipo se denomina intentar hacer demasiado a la vez. Por ejemplo, si se le pide a un agente que clone un sitio web como claude.ai, intentará completar toda la aplicación de una vez. Como resultado, el contexto no se ha aprovechado al máximo, se ha escrito la mitad de la funcionalidad y el código es un completo desastre. Al iniciar la siguiente sesión, solo puede contemplar con la mirada perdida el producto inacabado, dedicando mucho tiempo a adivinar qué se hizo en los pasos anteriores. El segundo tipo se denomina declarar la victoria prematuramente. Se completa una parte del proyecto, luego un agente posterior revisa el entorno, cree que está casi terminado y da por finalizado el proyecto. Se ignoran numerosas características faltantes. El tercer tipo se denomina prueba superficial. El agente modifica el código, ejecuta algunas pruebas unitarias o modifica la interfaz y cree que todo está bien, sin pasar por el proceso completo como un usuario real. El hilo conductor de estos tres modos de fallo es que el agente desconoce el objetivo global, ni sabe dónde detenerse ni qué dejar para el siguiente agente. ¿Cuál es entonces la solución de Anthropic? En esencia, estas son algunas soluciones fácilmente disponibles desde la ingeniería de software: introducir un mecanismo colaborativo similar al de un equipo humano, dividir las tareas complejas en tareas más pequeñas, rastreables y verificables, establecer mecanismos de entrega claros y verificar rigurosamente los resultados de las tareas. Un agente de inicialización aparece solo una vez al iniciar el proyecto. Su tarea es configurar el entorno de ejecución del proyecto. Es similar a un arquitecto: escribe un script init.sh para facilitar el inicio posterior del servidor de desarrollo, crea un archivo claude-progress.txt para registrar el progreso, realiza la primera confirmación de Git y, lo más importante, genera una lista de características. ¿Qué tan detallada es esta lista de funciones? En el caso de la clonación de claude.ai, se enumeran más de 200 funciones específicas, como permitir a los usuarios abrir nuevas conversaciones, introducir preguntas, pulsar Intro y ver las respuestas de la IA. Cada estado inicial se marca como fallido, y el agente debe verificar cada uno individualmente antes de poder cambiarlo a correcto. Además, hay un detalle: esta lista no está escrita en Markdown, sino como una matriz JSON. Esto se debe a que los experimentos de Anthropic demostraron que, en comparación con Markdown, los modelos son menos propensos a ser manipulados o sobrescritos arbitrariamente al procesar JSON. El otro es el agente de codificación. Tras la inicialización del proyecto, es responsable del trabajo. Sus directrices de comportamiento principales son solo dos: realizar una función a la vez y dejar un entorno limpio tras su finalización. ¿Qué constituye un entorno limpio? Imagina tus estándares para enviar código a la rama principal: sin errores graves, código limpio y bien documentado, para que la siguiente persona pueda empezar a trabajar en nuevas funciones inmediatamente sin tener que limpiar el desorden primero. Antes de cada operación, hace algunas cosas: – Ejecute `pwd` para ver en qué directorio se encuentra. – Lea los registros de Git y los archivos de progreso para comprender qué se hizo en la ejecución anterior. – Revise la lista de funciones y seleccione la función incompleta con mayor prioridad. – Ejecute una prueba básica para asegurarse de que la aplicación aún se pueda usar. Luego concéntrese en una característica y, una vez terminada: - Borrar el mensaje de confirmación de Git – Actualizar claude-progress.txt – Modifique únicamente los campos de estado en la lista de características, nunca elimine ni modifique los requisitos en sí. La ingeniosidad de este diseño reside en la externalización de la "memoria" en archivos e historial de Git. Cada ronda del agente no se basa en información fragmentada en la ventana de contexto; en cambio, imita las tareas diarias de un ingeniero humano confiable: primero, sincronizar el progreso, confirmar que el entorno funciona correctamente y luego comenzar a trabajar. Las mejoras en el proceso de pruebas merecen una discusión aparte. El agente solo utilizaba verificación a nivel de código, como la ejecución de pruebas unitarias o la llamada a API. El problema es que muchos errores solo aparecen cuando el usuario interactúa con la página. La solución es equipar al Agente con una herramienta de automatización del navegador, como Puppeteer MCP. Ahora, el Agente puede abrir un navegador, hacer clic en botones, completar formularios y ver los resultados de renderizado de páginas como si fuera una persona real. Anthropic publicó un GIF animado que muestra una captura de pantalla tomada por el Agente mientras probaba un clon de claude.ai, demostrando que efectivamente funciona como un usuario. Esta técnica mejora significativamente la precisión de la verificación funcional. Claro que tiene limitaciones. Por ejemplo, Puppeteer no puede capturar las alertas emergentes nativas del navegador, y las funcionalidades que dependen de ellas son propensas a errores. Este plan todavía deja algunas preguntas abiertas. Por ejemplo, ¿es mejor tener un agente de propósito general que lo gestione todo o tener roles especializados? Quizás sería más efectivo tener un agente de pruebas específico para las pruebas y un agente de limpieza de código específico para la limpieza. Por ejemplo, este conjunto de experiencia está optimizado para el desarrollo web integral. ¿Es posible transferirlo a tareas de ciclo largo como la investigación científica o el modelado financiero? Debería ser posible, pero debe verificarse mediante experimentos. Xiangma@xicilion dijo: Al final de la IA, todavía queda la ingeniería de software. Los agentes de IA no son mágicos. También necesitan aprender de la experiencia humana en ingeniería de software, simplificar las tareas complejas, contar con un entorno de trabajo estructurado y un mecanismo de transferencia claro. ¿Por qué pueden los ingenieros humanos colaborar entre equipos y zonas horarias? Porque cuentan con Git, documentación, revisión de código y pruebas. Para que los agentes de IA trabajen de forma autónoma durante periodos prolongados, también necesitan incorporar estas herramientas. El enfoque de Anthropic simplemente transforma las mejores prácticas de ingeniería de software en palabras clave y cadenas de herramientas que el agente puede comprender. No aumenta la inteligencia del modelo, sino que lo estructura mejor. Vale la pena aprender del enfoque de Anthropic. Ya sea que uses Claude, GPT u otro modelo, al diseñar tareas largas de varias rondas, necesitas comprender claramente cómo llevar al agente a la siguiente ronda rápidamente y cómo evitar que reinvente la rueda o cree un código desordenado. Incluso con tareas de una sola ronda, debes comprender que no tienen memoria; necesitas usar archivos externos para ayudarles a recordar lo que han hecho antes. Con las capacidades actuales del modelo, Coding Agent ya ofrece una gran variedad de funciones. La clave reside en la capacidad de desglosar tareas y diseñar flujos de trabajo de forma similar a la ingeniería de software. Texto original: Arneses efectivos para agentes de larga duración https://t.co/tERUGrV9wC traducir:
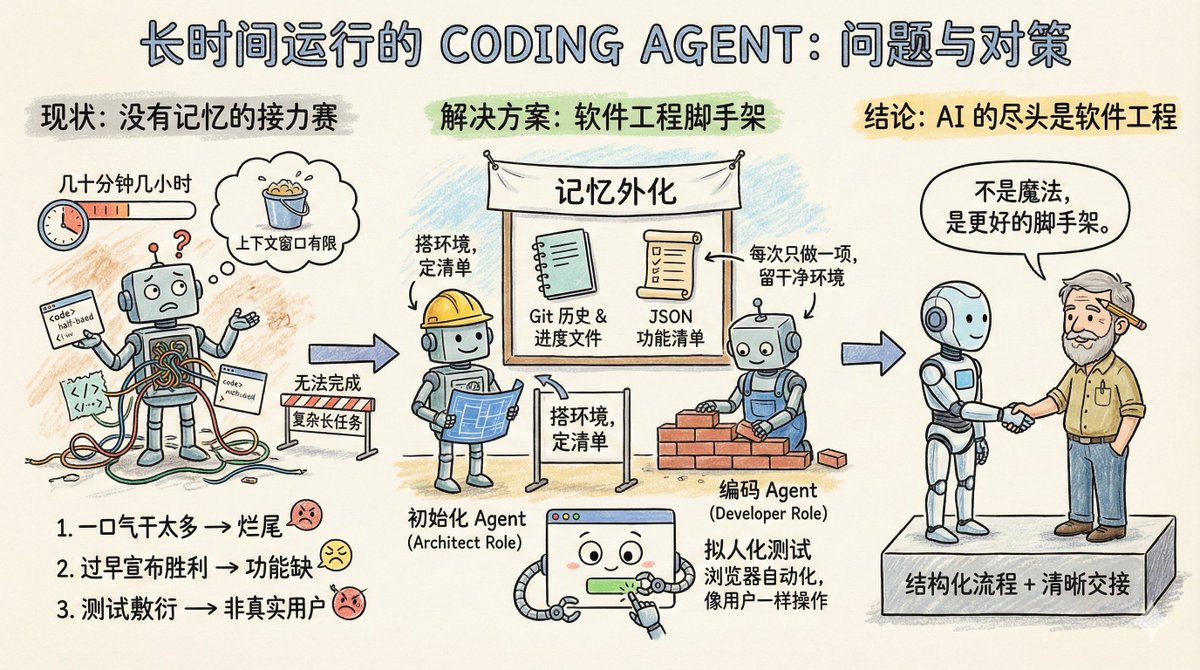
La lista de tareas mencionada en el artículo es un tipo de cox.com/stevenlu1729/s…o todos los contextos globales, no puede ser demasiado larga, de lo contrario la ventana de contexto para ejecutar tareas no sería suficiente.