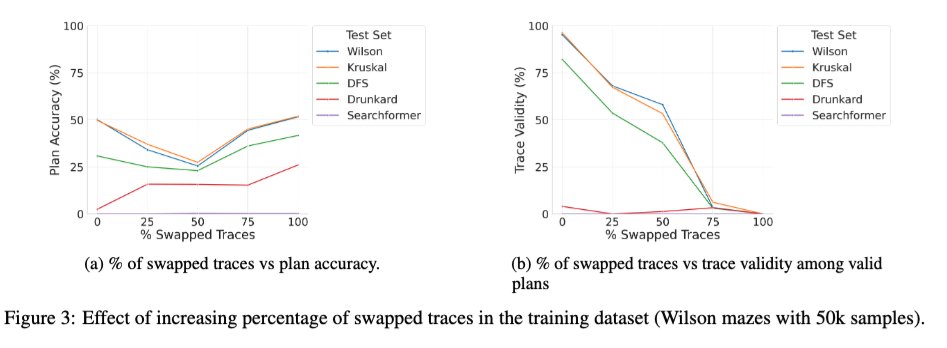
Acabamos de subir una versión ampliada del artículo "Más allá de la semántica" (nuestro estudio sistemático del papel de los tokens intermedios en los LRM) a arXiv, y puede que sea de interés para algunos de ustedes. 🧵 1/ Un nuevo estudio intrigante es el efecto de entrenar el transformador base con una combinación de trazas correctas e incorrectas. Observamos que, a medida que el porcentaje de trazas incorrectas (intercambiadas) durante el entrenamiento pasa de 0 a 100, la validez de las trazas de los modelos en el momento de la inferencia disminuye monótonamente (gráfico a la derecha abajo), como se esperaba, pero la precisión de la solución presenta una curva en U (gráfico a la izquierda). Esto sugiere que lo que parece importar es la consistencia de las trazas utilizadas durante el entrenamiento, más que su exactitud.
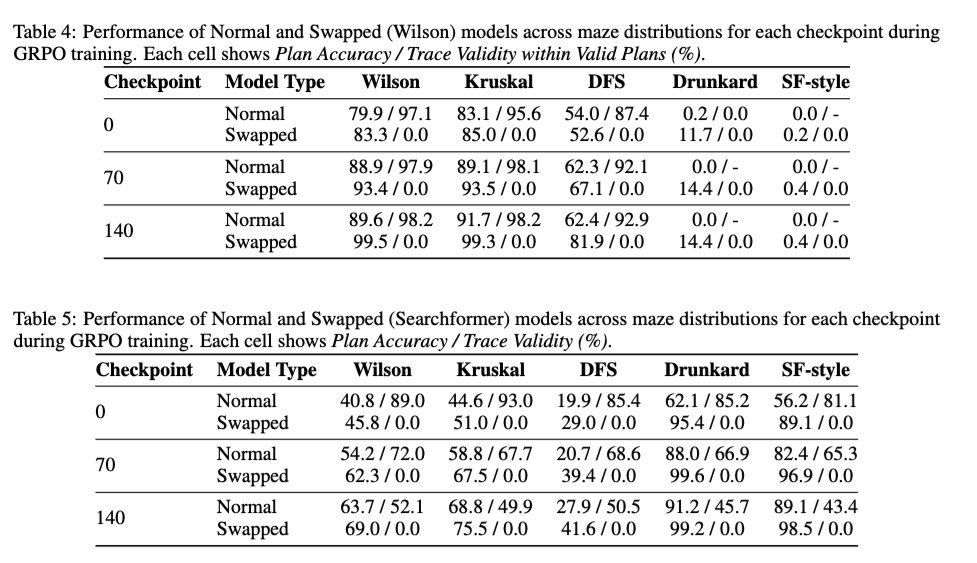
2/ También analizamos el efecto del RL estilo DeepSeek R1 en la validez de las trazas para determinar si mejora la validez de las trazas del modelo base. Los resultados muestran que el RL es prácticamente neutral en cuanto a la validez de las trazas. Mejora la precisión de la solución incluso en el caso de modelos entrenados con trazas 100% intercambiadas, sin aumentar la validez de las trazas.
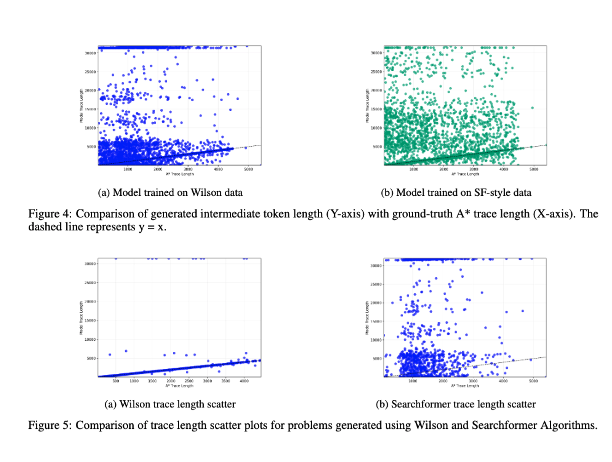
3/ Finalmente, incluimos un estudio de la correlación entre la longitud de los tokens intermedios y la complejidad computacional de la instancia del problema. Los resultados muestran que no existe correlación entre ellos. (Analicé una versión anterior de este experimento en https://t.co/RL9ZEOKbpQ).
4/ La nueva versión está disponiblearxiv.org/abs/2505.13775CZ5e. Estos resultados también serán presentados por los autores principales @karthikv792, @kayastechly y @PalodVardh12428 en los talleres #NeurIPS2025 sobre Derecho, ForLM y Razonamiento Eficiente la próxima semana. ¡Visítenos y charlemos!