Vale la pena leer este artículo de la Universidad de Stanford 👇🏻 Construyeron un marco de agente de IA, comenzando desde cero datos, sin anotaciones humanas, tareas cuidadosamente diseñadas o demostraciones, pero superó todos los métodos de autojuego existentes. Este marco se llama Agent0: libera a los agentes inteligentes en evolución propia a partir de datos cero integrando la inferencia a través de herramientas. Sus logros son increíbles. Todos los agentes de “automejora” que has visto antes tienen un defecto fatal: solo pueden generar tareas que son ligeramente más difíciles de lo que ya conocen, por lo que inmediatamente se encuentran con un cuello de botella. El agente0 rompió este techo. El punto clave es: Generan dos agentes a partir del mismo LLM subyacente y los dejan competir. • Agente de curso: Genera tareas de dificultad creciente. • Agente de ejecución: Intenta resolver estas tareas mediante razonamiento y herramientas. Cada vez que el agente ejecutor mejora, el agente del curso se ve obligado a aumentar la dificultad. Cada vez que la tarea se vuelve más difícil, el agente ejecutor se ve obligado a evolucionar. Esto creó una espiral curricular de circuito cerrado que se reforzaba a sí misma, y todo empezó desde cero, sin datos, sin personas y sin nada. Es simplemente que los dos agentes inteligentes se empujan mutuamente para alcanzar un mayor nivel de inteligencia. Luego agregaron códigos de trucos: Un intérprete de herramientas Python completo está en un bucle. El agente de ejecución aprende a razonar sobre los problemas a través del código. El agente del curso aprende a crear tareas que requieren el uso de herramientas. Por lo tanto, ambos agentes inteligentes se actualizan constantemente. ¿Y cuál fue el resultado? → La capacidad de razonamiento matemático mejoró en un +18% → La capacidad de razonamiento general aumentó en un 24% → Supera a R-Zero, SPIRAL, Absolute Zero e incluso a marcos que utilizan API propietarias externas → Todos ellos se originan a partir de datos cero, simplemente un ciclo en autoevolución. Incluso demostraron que la curva de dificultad aumenta durante el proceso de iteración: la tarea comienza con geometría básica y eventualmente llega a problemas que involucran satisfacción de restricciones, combinatoria, acertijos lógicos y problemas de múltiples pasos que dependen de herramientas. Esto es lo más cercano que hemos visto al crecimiento cognitivo autónomo en LLM. Agent0 es más que simplemente "mejor RL". Es un modelo para que los agentes inteligentes guíen su propia inteligencia. Se ha desbloqueado la era de los agentes inteligentes.

Antes de empezar a leer, recuerda darle mexaicreator.comrdar esta publicación. Este contenido en Threads fue publicado por un motor de contenido colaborativo humano-computadora. https://t.co/Gxsobg3hES
Idea central: Agent0 crea dos agentes a partir del mismo LLM subyacente y los obliga a participar en un ciclo de retroalimentación competitivo. Uno inventa una tarea, el otro intenta sobrevivir. Este tira y afloja continuo crea un problema de dificultad de vanguardia, incomparable con cualquier conjunto de datos estáticos.
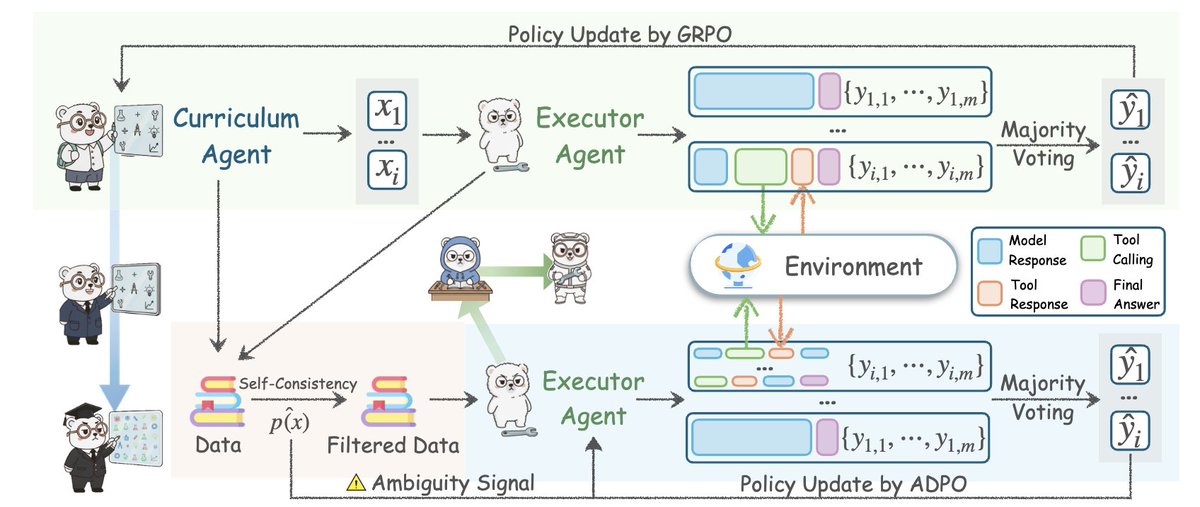
El avance no reside en el juego autónomo, sino en el razonamiento integrado con herramientas. El agente ejecutivo puede ejecutar código Python dentro de la solución, obtener el resultado y actualizar su razonamiento. Esto permite al agente curricular responder creando preguntas que requieren el uso de herramientas. Un círculo virtuoso.

Abordaron el principal modo de fallo de los agentes autoevolutivos: el estancamiento. La mayoría darxiv.org/abs/2511.16043ran problemas ligeramente más complejos que su nivel actual. Agent0 utiliza la incertidumbre, la divergencia entre las respuestas muestreadas y la frecuencia de llamadas a herramientas para detectar debilidades en el agente en ejecución. Lea el artículo completo aquí: https://t.co/7UheEMgrBw

En mi opinión, esto utiliza esencialmente LLM para construir dos agentes que compitan, lo cual también es una especie de lógica de pensamiento GAN. En otras palabras, el desarrollo se forma en el proceso de resolver constantemente el conflicto entre el Yin y el Yang. Sin embargo, para que este sistema funcione, es fundamental dotar a los agentes de la capacidad de "buscar y crear herramientas". Mientras posean esta capacidad, podrán interactuar continuamente con el mundo a través del aprendizaje directo y, finalmente, encontrar soluciones a los problemas. Esto es similar a la práctica humana.
Por último, ¡gracias por tomarte el tiempo de leer este tweet! Siga a @Yangyixxxx para obtener información sobre IA, conocimientos comerciales y estrategias de crecimiento. Si te ha gustado este contenido, dale me gusta y comparte el primer tweet para difundir información valiosa a más personas.