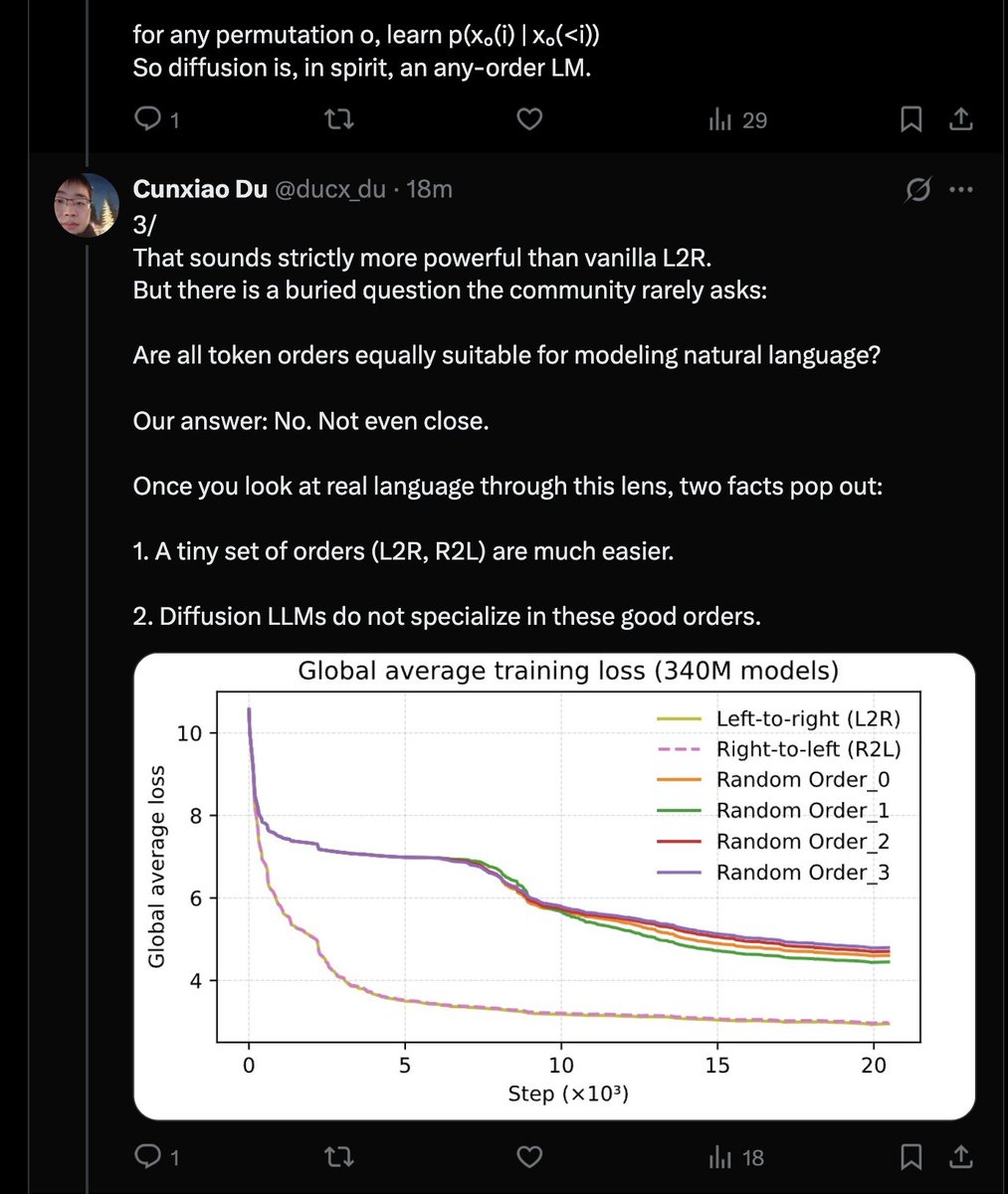
Una narrativa extremadamente poderosa. Los modelos de difusión por defecto carecen de sentido porque el lenguaje es markoviano y los órdenes L2R o R2L son estrictamente superiores. Parece que la única forma sensata de entrenar DLLM es con la pérdida de suma logarítmica.