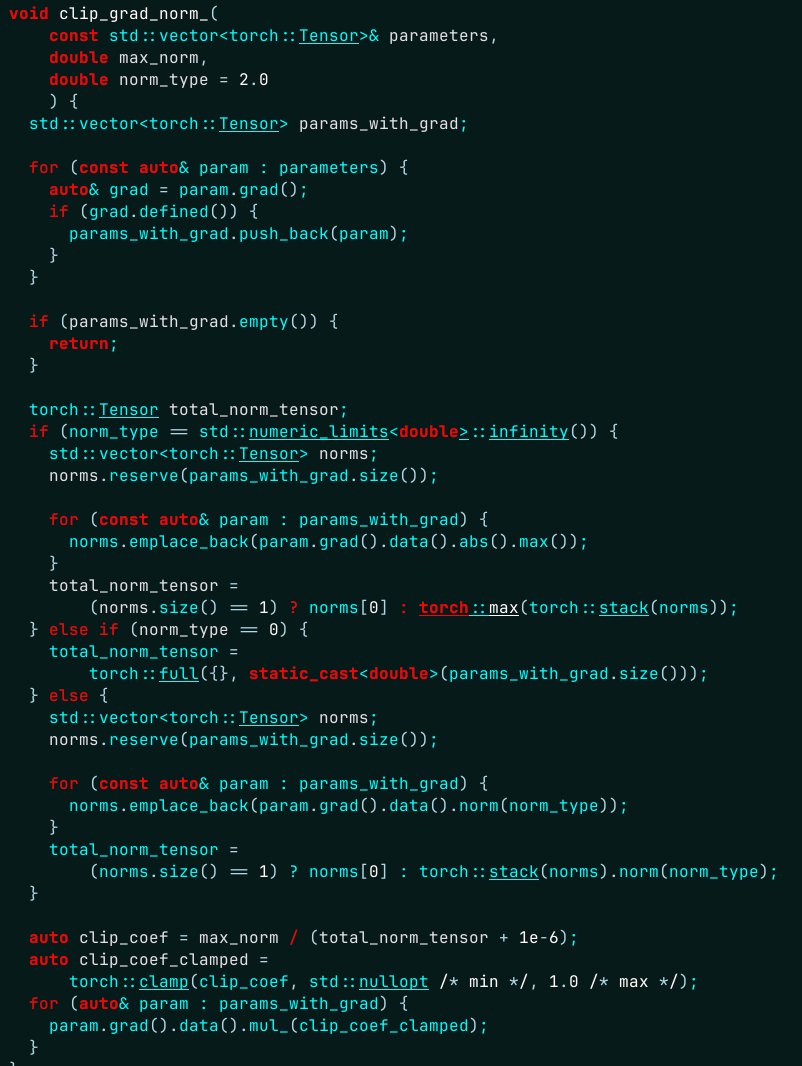
Pasé una hora tratando de averiguar de dónde venían varios cientos de sincronizaciones CUDA adicionales... en serio, una antorcha... // Diferencia con la versión de Python: a diferencia de la versión de Python, incluso cuando // omitiendo las comprobaciones de finitud (error_if_nonfinite = false), esta función // introducirá una sincronización de dispositivo CPU (para dispositivos donde eso hace // ¡Sentido!) para devolver un `double` del lado de la CPU. Por lo tanto, esta versión de C++ // no se puede ejecutar de forma totalmente asincrónica con respecto al dispositivo de los gradientes.
Se sincronizaba sin ningún motivo... solucionado aquí