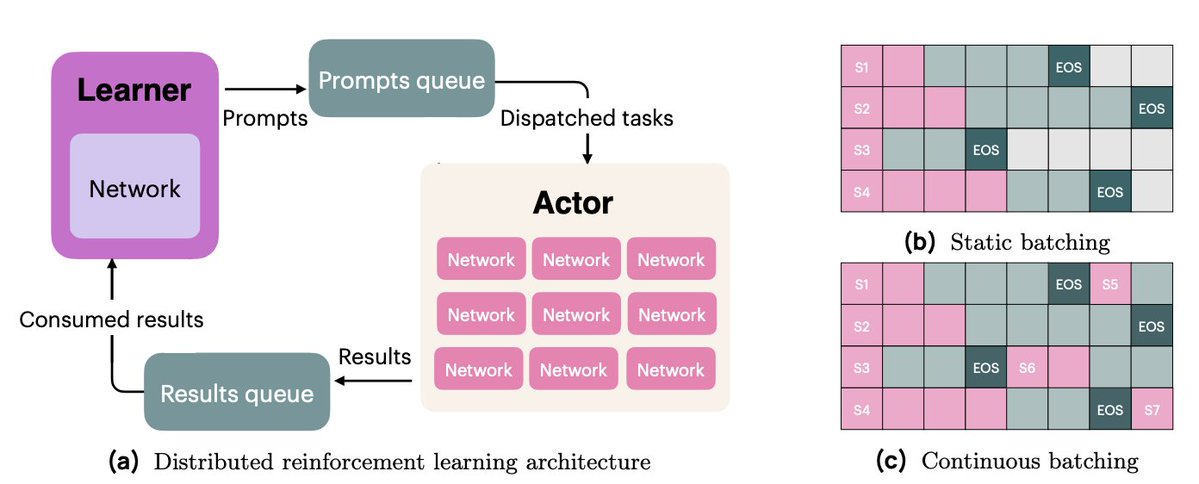
La infraestructura de OlmoRL era cuatro veces más rápida que la de Olmo 2 y abarataba considerablemente la realización de experimentos. Algunos de los cambios: 1. dosificación continua 2. Actualizaciones en vuelo 3. muestreo activo 4. Muchas mejoras en nuestro código multihilo
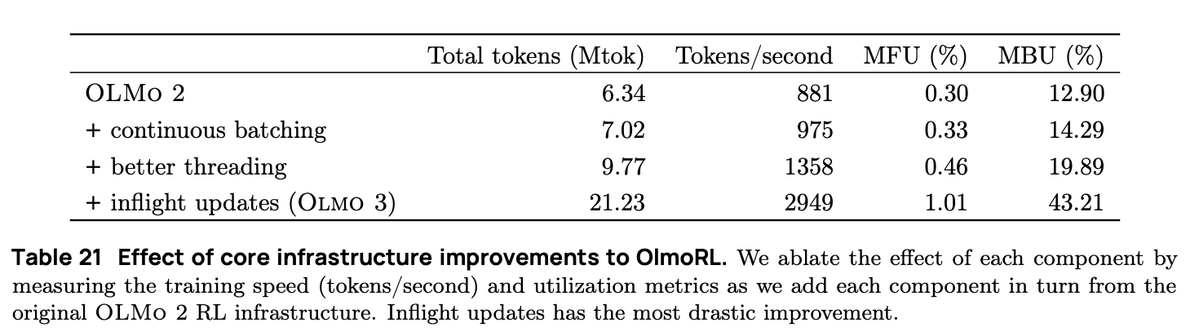
En el procesamiento por lotes continuo, pasamos a una configuración de generación totalmente asíncrona, donde tenemos dos colas: una para las solicitudes y otra para los resultados de la generación. Nuestros actores operan de forma totalmente asíncrona, generando continuamente nuevas indicaciones a medida que finalizan las anteriores.
Con las actualizaciones en tiempo real (PipelineRL, de @alexpiche_, @DBahdanau y otros), actualizamos nuestros actores en medio de la generación. El sistema es mucho más rápido, ya que no tenemos que vaciar las colas de generación para actualizar los pesos (lo cual es el mismo problema que con el procesamiento por lotes estático).

El muestreo activo (una novedosa contribución de @mnoukhov) resuelve un problema maldito que ocurre en GRPO donde los grupos con varianza 0 en la recompensa (y por lo tanto ventaja 0, por lo tanto un gradiente 0) se filtran, lo que provoca que el tamaño del lote varíe en cada paso de entrenamiento.
En trabajos anteriores se solucionó el problema del tamaño variable de los lotes muestreando el triple de los grupos necesarios, con la esperanza de contar siempre con suficientes grupos tras el filtrado. En cambio, Michael modificó nuestro código para esperar hasta tener un lote completo de grupos con recompensas no constantes antes del entrenamiento.
Esto requirió una serie de tareas complicadas para mantener sincronizados a nuestros actores y alumnos.
Finalmente, dedicamos muchísimo tiempo a refactorizar nuestro código para reducir la sincronización y permitir que nuestros actores operaran de forma asíncrona. Esto implicó un extenso trabajo de ingeniería con las API de hilos y asyncio de Python.
Nuestro trabajo de infraestructura de RL fue un esfuerzo de grupo, con contribuciones mías, de @hamishivi, @mnoukhov, @saurabh_shah2 y @tyleraromero, y se basó en los fundamentos que dejó para usar @vwxyzjn.
Para obtener más información sobre nuestro trabajo, consulte el artículo, la entrada del blog y el trabajo relacionado, incluida nuestrx.com/natolambert/st…que comienza a las 9 a. m. PT.