El conjunto de datos oficial SYNTH de nanochat en inglés está casi terminado: ¿alguien con experiencia en entrenamiento de nanochat que quiera probar cuál sería el mejor enfoque? Normalmente se trata de una adaptación mínima (ya está fragmentado), pero el script de importación del conjunto de datos está integrado en FineWeb.
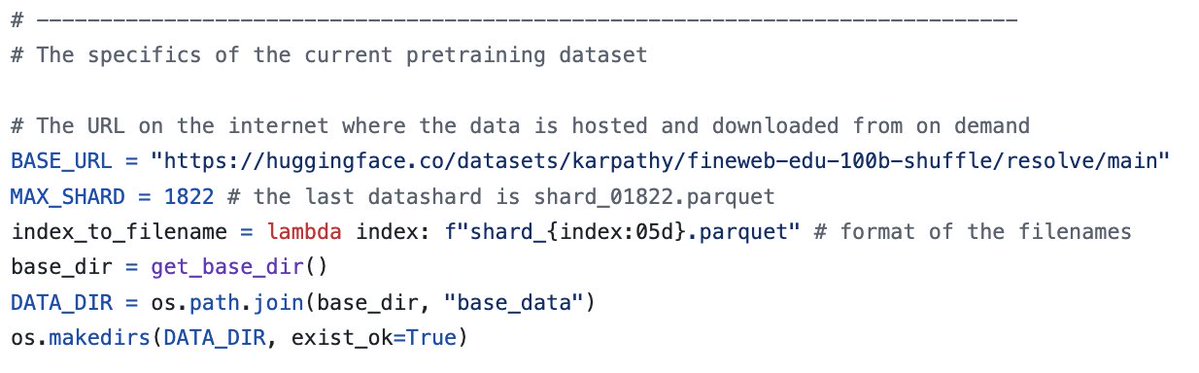
De lo contrario, el archivo .sh principal debería ser en su mayor parte una simplificación: con SYNTH no se necesitan etapas separadas para el preentrenamiento, el entrenamiento intermedio y el postentrenamiento.