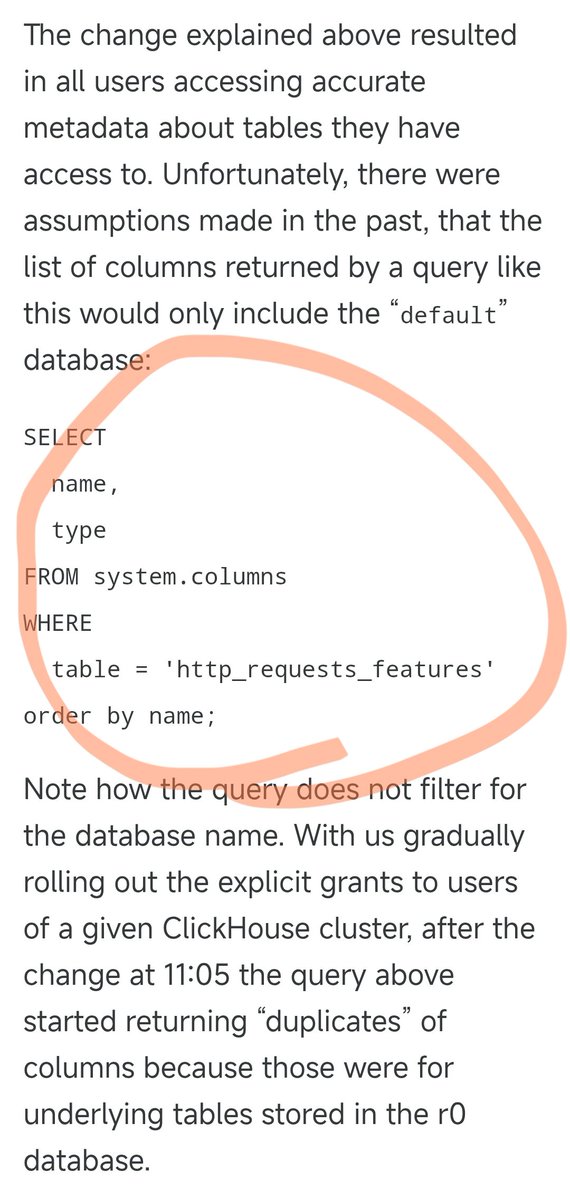
La interrupción del servicio de Cloudflare anoche fue causada por la siguiente instrucción SQL. Anteriormente, esta consulta SQL funcionaba perfectamente, consultando únicamente la información de las columnas en la base de datos predeterminada. Sin embargo, ayer actualizaron los permisos de algunos usuarios, lo que provocó que esta consulta SQL devolviera información de solución tanto de la base de datos predeterminada como de la base de datos r0 subyacente. Al ajustar los permisos, nadie pensó en modificar la consulta SQL en consecuencia. Como resultado, el número de resultados de la consulta se duplicó, lo que provocó que el tamaño del archivo de resultados también se duplicara. El archivo que originalmente contenía alrededor de 60 elementos pasó a contener alrededor de 120 elementos. Esto nos lleva a una característica de diseño clave. Para optimizar el rendimiento, el módulo anti-rastreo de Cloudflare preasigna una cantidad fija de memoria y establece un límite máximo: admite un máximo de 200 funciones. El límite se estableció originalmente de forma bastante laxa, ya que en realidad solo se utilizaron 60, dejando más del triple del margen. Sin embargo, surgen problemas cuando el archivo de características supera el límite de 200 características debido a datos duplicados. El código Rust incluye una comprobación que genera un error 500 si el número de características excede el límite. Peor aún, este archivo de características se genera automáticamente cada 5 minutos y se envía rápidamente a todos los servidores del mundo. Debido a que los ajustes de permisos se aplican a cada nodo de la base de datos de forma incremental, cada 5 minutos, dependiendo del nodo en el que se ejecute la consulta, se puede generar un archivo correcto o uno incorrecto. Esto dio lugar a un fenómeno muy extraño: el sistema funcionaba y luego fallaba intermitentemente, a veces volviendo a la normalidad y otras veces colapsando por completo. Este síntoma hizo sospechar a los ingenieros que podría estar sufriendo un ataque DDoS. Casualmente, la página de estado de Cloudflare (alojada por un tercero y completamente independiente de la infraestructura de Cloudflare) también se cayó en ese momento, lo que profundizó aún más las sospechas de un "ataque". Esto les llevó a pensar en la dirección equivocada al identificar el problema, perdiendo así algo de tiempo. No fue hasta que los ajustes de permisos se implementaron gradualmente en todos los nodos y cada uno comenzó a generar archivos corruptos, que el sistema entró en un estado de fallo estable. Solo entonces los ingenieros pudieron finalmente identificar el problema real y solucionarlo. La interrupción del servicio comenzó alrededor de las 19:28 del 18 de noviembre en Pekín, se restableció inicialmente a las 22:30 y se completó a la 01:06 del 19, con una duración total de aproximadamente 5,5 horas. Fue la mayor interrupción de Cloudflare desde 2019.