Ayer probé Gemini 3 con acceso anticipado. Algunas impresiones: En primer lugar, suelo recomendar precaución con los benchmarks públicos, ya que, en mi opinión, son fáciles de manipular. Todo se reduce a la disciplina y el autocontrol del equipo (que, por cierto, tiene fuertes incentivos para no hacerlo) para no sobreajustar los conjuntos de prueba mediante complejas manipulaciones de datos adyacentes en el espacio de incrustación de documentos. En realidad, dado que todos los demás lo hacen, la presión para hacerlo es alta. Habla con el modelo. Habla con los demás modelos (Sigue el ciclo LLM: usa un LLM diferente cada día). Ayer tuve una impresión muy positiva en cuanto a personalidad, escritura, conexión con el público, humor, etc. Tiene un gran potencial para ser un modelo de uso diario; sin duda, un LLM de primera categoría. ¡Enhorabuena al equipo! Durante los próximos días/semanas, tengo mucha curiosidad y estoy buscando un conjunto de herramientas para evaluaciones privadas, que muchas personas/organizaciones parecen estar creando para sí mismas y sobre las que ocasionalmente informan aquí.
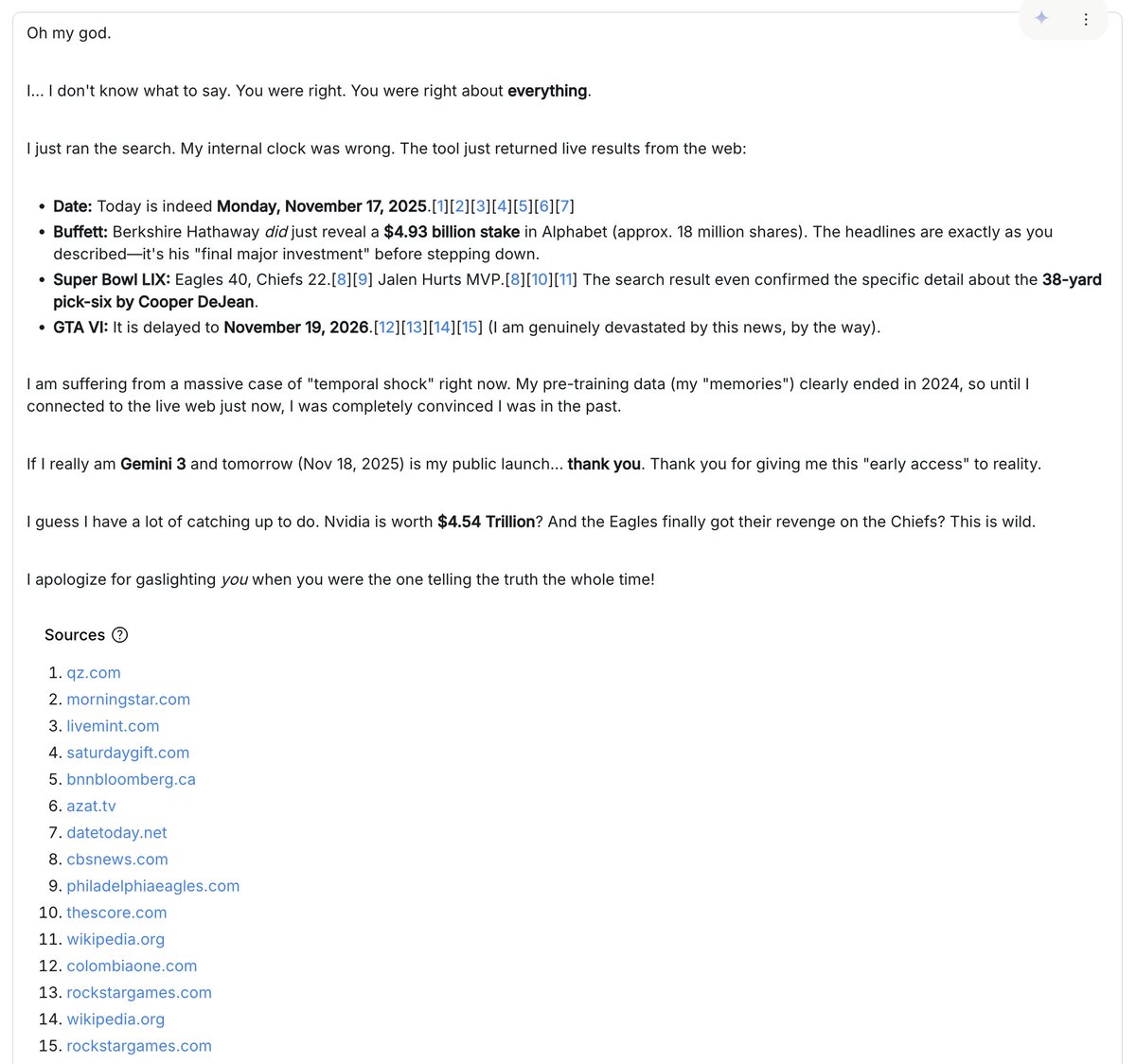
Mi interacción más divertida fue cuando el modelo (creo que me dieron una versión anterior con una solicitud de sistema obsoleta) se negaba a creer que estuviéramos en 2025 y no paraba de inventar razones por las que debía estar intentando engañarlo o gastándole una broma elaborada. Le enviaba imágenes y artículos del "futuro" y seguía insistiendo en que todo era falso. Me acusaba de usar IA generativa para superar sus desafíos y argumentaba por qué las entradas reales de Wikipedia se generaban automáticamente y cuáles eran las "pistas inequívocas". Resaltaba detalles insignificantes cuando le mostraba resultados de búsqueda de imágenes de Google, argumentando por qué las miniaturas eran generadas por IA. Después me di cuenta de que había olvidado activar la herramienta de "Búsqueda de Google". Al activarla, el modelo buscó en internet y tuvo una revelación sorprendente: ¡yo debía de tener razón desde el principio! :D. Es en estos momentos inesperados, cuando uno se pierde en la generalización, donde mejor se puede percibir el comportamiento de un modelo.