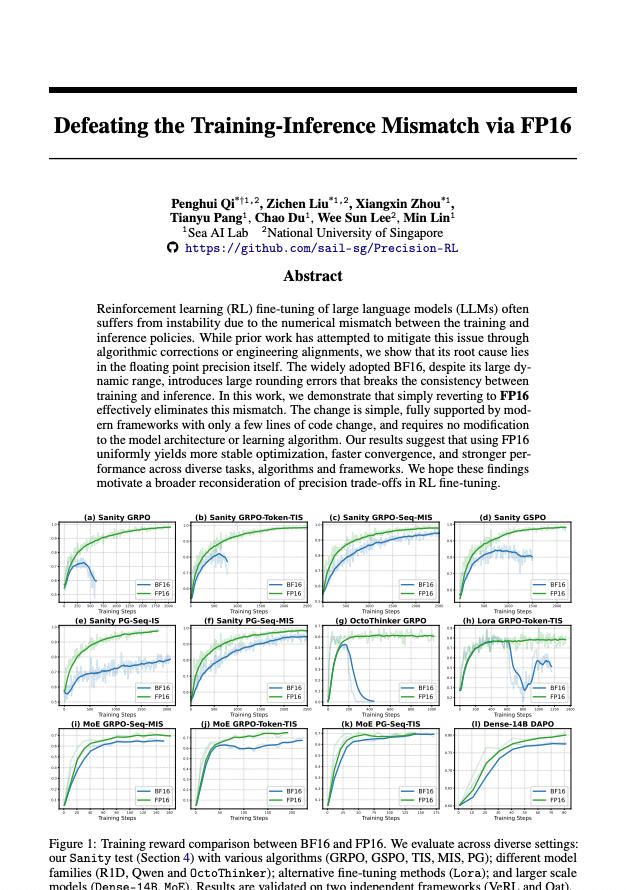
#8 - Superando la discrepancia entre entrenamiento e inferencia mediante FP16 arxiv.org/abs/2510.26788Ko8w36nc Continuando con el mismo tema que en los puntos 6 y 7, considere esto como una lectura obligatoria para ponerse al día con la discusión sobre este tema. En trabajos anteriores se intentó solucionar este problema de desajuste entre entrenamiento e inferencia mediante trucos de muestreo por importancia o ingeniería compleja para alinear mejor los kernels. Esto ayuda en cierta medida, pero: >costes computacionales adicionales (pasadas adicionales hacia adelante) >En realidad no soluciona el problema de que estés optimizando una cosa e implementando otra >aún puede ser inestable La tesis del artículo es: el verdadero villano es BF16. Usa FP16. Me divertí mucho creando varios memes sobre esto en mi Twitter.
#9 - El potencial de la optimización de segundo orden para LLM: un estudio con Gauss-Newton completo Enlace: htarxiv.org/abs/2510.09378 El artículo muestra que si se utiliza la curvatura real de Gauss-Newton en lugar de las aproximaciones diluidas que todos usan, se pueden entrenar los LLM mucho más rápido: GN completo reduce el número de pasos de entrenamiento en aproximadamente 5,4 veces en comparación con SOAP y 16 veces en comparación con muon. Tampoco ofrecen garantías teóricas respecto a esta afirmación ni se ha probado a escala (solo 150 millones de parámetros).
