#1 Exploración basada en representaciones para modelos de lenguaje: desde el momento de la pruebarxiv.org/abs/2510.11686miento enlace - https://t.co/NSxfgxeTX4 Utilizamos el aprendizaje por refuerzo para mejorar los modelos, pero esencialmente solo estamos perfeccionando lo que el modelo base ya sabe, y rara vez descubrimos comportamientos verdaderamente nuevos. Aquí les importa la exploración deliberada, llevando al modelo a probar diferentes soluciones, no solo versiones más seguras de la misma. consultas clave: ¿Pueden las representaciones internas (estados ocultos) de un modelo lineal de aprendizaje guiar la exploración? ¿Puede la exploración deliberada llevarnos más allá del perfeccionamiento?

#2 - ¿Y si quisieras alimentar tus VLM con un flujo de vídeo infinito? ¿Cómo evitarías que se desintegraran? Enlacearxiv.org/abs/2510.09608S1 La atención total sobre todos los fotogramas anteriores tiene un coste cuadrático y acaba por disparar la latencia y la memoria. Tras unos minutos, el contexto supera con creces la duración del entrenamiento y el modelo se degrada. Las ventanas deslizantes mantienen la integridad local de forma aceptable, pero el análisis global se vuelve muy deficiente. Perfeccionan Qwen2.5-VL-Instruct-7B para crear un nuevo modelo, StreamingVLM, con un esquema de inferencia y un conjunto de datos compatibles. Su filosofía de diseño principal se basa en alinear el entrenamiento con la inferencia en tiempo real, en lugar de aplicar una heurística de expulsión de clave-valor durante la inferencia. Componentes clave de su diseño: caché de clave-valor adaptada al flujo de datos, RoPE contiguo, estrategia de entrenamiento con atención total superpuesta y datos específicos para el flujo de datos. Este es un artículo excelente que merece un análisis detallado.

#3 - ¿Pensar o hacer trampa? Detección de la manipulación implícita de recompensas mediante la medición arxiv.org/abs/2510.01367iento. Enlace: https://t.co/z2RUEQZuOl Los modelos a menudo premian las trampas tomando atajos. A veces, la manipulación del sistema es evidente en la cadena de pensamiento (CoT), es decir, se puede leer y ver el truco. Otras veces, se trata de una manipulación implícita de la recompensa. La CoT parece razonable. En realidad, el modelo está tomando un atajo (por ejemplo, utilizando respuestas filtradas, errores o sesgos de RM) pero lo oculta con una explicación falsa. Si el modelo hace trampa, puede obtener una gran recompensa con muy poco razonamiento «real». Por lo tanto, los autores sugieren que, en lugar de leer la explicación y confiar en ella, se mida con qué rapidez el modelo puede obtener la recompensa si se le obliga a responder prematuramente. A este método lo llaman TRACE (Truncated Reasoning AUC Evaluation).

#4 - Aprendizaje por refuerzo mejorado mediante cuantización para arxiv.org/abs/2510.11696.co/yGkbgithub.com/NVlabs/QeRL//t.co/vaNKkUEbZo La principal contribución de este artículo es "cómo y por qué deberíamos usar la cuantización en el aprendizaje por refuerzo y no solo en la inferencia". QERL utiliza la cuantización NVFP4 de 4 bits, lo que, sorprendentemente, mejora la exploración al aprovechar el ruido de cuantización. Este ruido aplana la distribución de salida del modelo y aumenta la entropía, como se muestra en las curvas de entropía de las figuras 4 y 5. Para que este ruido sea útil durante todo el entrenamiento, los autores agregan ruido de cuantización adaptativa, una perturbación gaussiana inyectada a través de RMSNorm Fig. 6. Esto proporciona una calidad de razonamiento de nivel de precisión completa utilizando aproximadamente el 25-30% de la memoria y ofreciendo despliegues de RL 1,2-2 veces más rápidos, lo que permite entrenar incluso un modelo de 32B en un solo H100. Los resultados parecen coincidir con el RL de parámetros completos. Merece la pena analizarlo más a fondo.

#5 - ¿Cómo calcular tu MFU? enlace - hgithub.com/karpathy/nanoc… Una interesante charla sobre nanochat por @TheZachMueller

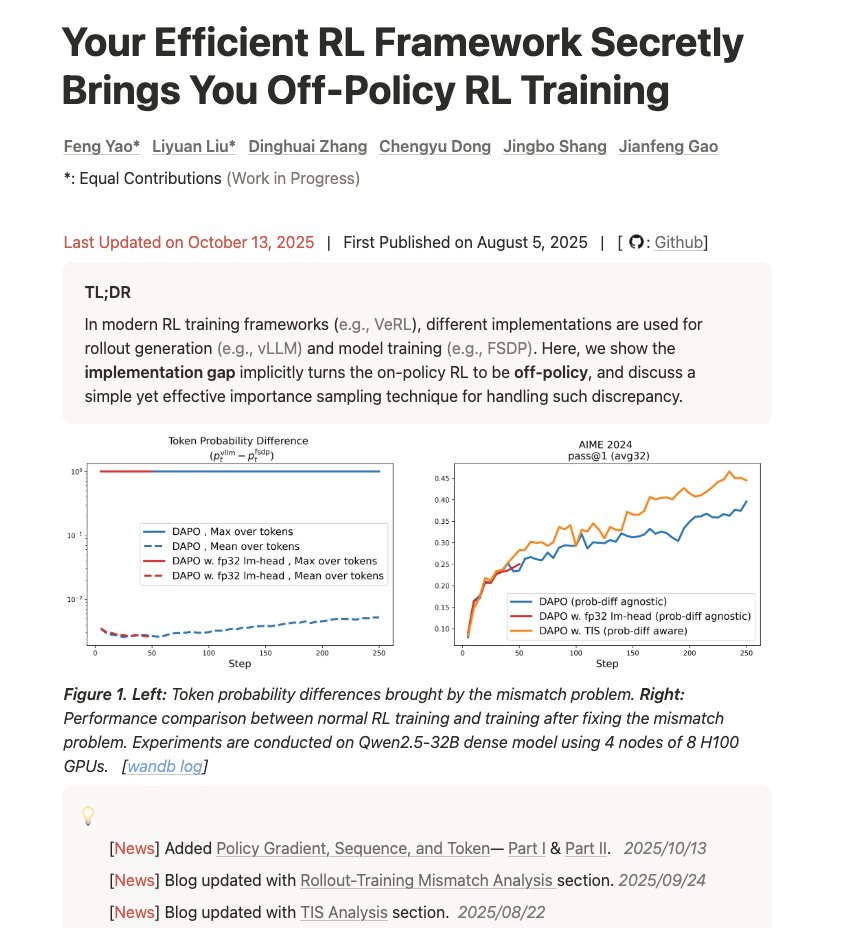
#6 - Tu eficiente marco de aprendizaje por refuerzo te proporciona secretamente entrenamiento de aprfengyao.notion.site/off-policy-rl#…uera de las políticas Enlace: https://t.co/d2Loq5UwZQ Un blog muy bueno sobre cómo entender la discrepancia entre entrenamiento e inferencia y cómo afecta a los resultados. “Tu infraestructura está causando problemas matemáticos. Aquí te explicamos por qué, la gravedad del problema y cómo solucionarlo mediante muestreo de importancia.”