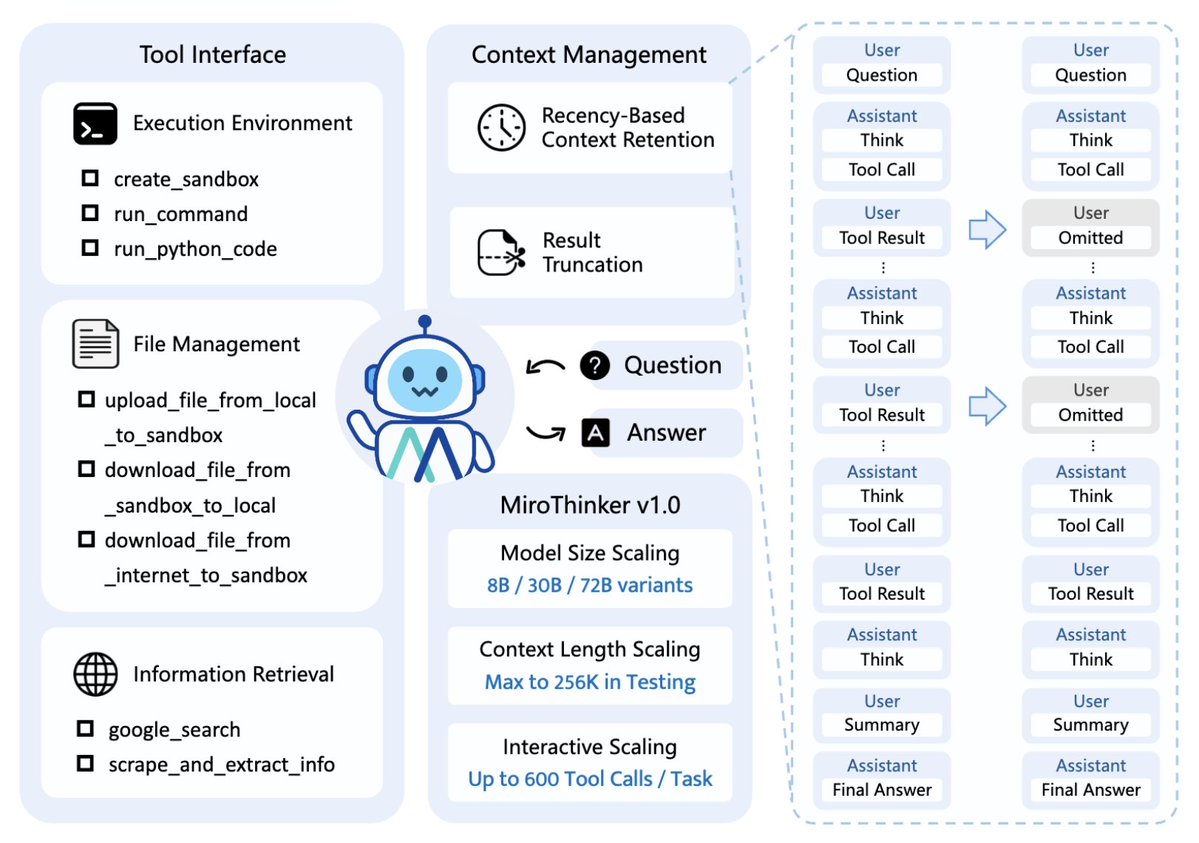
El equipo de MiroMind ha lanzado un nuevo modelo bAgent de código abierto: MiroThinker v1.0. Su mayor innovación reside en la introducción de un nuevo concepto: "Escalado interactivo". Superar el cuello de botella de la Ley de Escala, permitiendo que la IA evolucione por sí misma. Este concepto rompe con el patrón de crecimiento lineal tradicional de "cuanto mayor sea el tamaño del modelo, mejor será el rendimiento" y, en cambio, enfatiza que "la profundidad y la frecuencia de la interacción entre el modelo y el entorno" son los factores clave para un crecimiento inteligente. MiroThinker admite múltiples interacciones e inferencias con herramientas externas (como motores de búsqueda, entornos aislados de Linux, reconocimiento de voz, etc.), lo que permite a los usuarios utilizar las herramientas de forma flexible para obtener información y completar tareas. - 256K Contexto: Puede recordar una gran cantidad de información (cientos de miles de palabras). - Se pueden ejecutar hasta 600 llamadas a herramientas a la vez: la IA puede utilizar continuamente herramientas externas como búsqueda, ejecución de código, cálculo y traducción. - Capaz de realizar razonamientos complejos y tareas de larga duración: no solo responder preguntas, sino pensar paso a paso, investigar información y comparar soluciones. ¿Qué es el "Escalamiento de Interacción Profunda"? Rendimiento ∝ Profundidad de interacción modelo-entorno × Frecuencia de reflexión En otras palabras: - El modelo no absorbe pasivamente el conocimiento, sino que interactúa activamente con el entorno; Cada ensayo y error, junto con la reflexión, permite que el modelo "evolucione" en el ámbito de las políticas; Cuanto más "actúe" la IA, más podrá corregir errores y mejorar la calidad de su razonamiento. Del mismo modo que los seres humanos solo pueden aprender verdaderamente cosas complejas a través de la repetición de ensayos y errores y la práctica directa. 🧩 Por ejemplo: Al igual que ocurre con los humanos al aprender a cocinar, simplemente mirar recetas no es suficiente; uno debe intentarlo, equivocarse, corregir y volver a intentarlo personalmente. Para la IA, múltiples rondas de interacción con el entorno, junto con la retroalimentación correctiva, constituyen el verdadero combustible para la evolución inteligente. Cada interacción representa una oportunidad de aprendizaje, y la inteligencia se fortalece progresivamente. Por lo tanto, MiroThinker lleva al límite tanto la "longitud del contexto" como el "número de rondas de interacción", formando un verdadero "bucle de pensamiento".
En múltiples evaluaciones internacionales Puntuaciones cercanas o incluso superiores a la versión avanzada de GPT-5: Obtuvo un 47,1% en la prueba BrowseComp para comprender páginas web complejas, acercándose a DeepResearch de OpenAI (51,5%). Superó a GPT-5-high en la Prueba de Razonamiento Humano Definitivo (HLE). Supera a DeepSeek-v3.2 en aproximadamente 7,7 puntos porcentuales en tareas en idioma chino.

Totalmente de código abierto y reproducible Todos los recursos principales de MiroThinker v1.0 soxiaohu.ai/c/a066c4/mirot…cluyendo:github.com/MiroMindAI/Mir…- Marco de razonamiento e interacción - Infraestructura de entrenamiento y aprendizaje por refuerzo - Conjunto de datos de evaluación - Informe técnico completo Introducción detallada: https://t.co/wpST53dHtd GitHub: https://t.co/KQZr8sTcby