¿Por qué aceptamos la distribución aproximada a partir de datos/modelo con KL hacia adelante (imagen izquierda)? ¿Por qué no trabajar en algoritmos que se parezcan a (imagen de la derecha)?
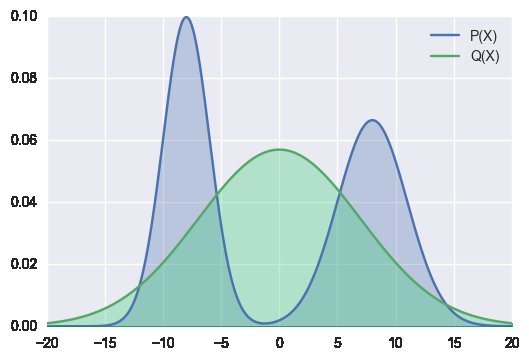

¿O acaso ya lo hacemos porque estamos minimizando KL con un sesgo de actualidad mayor en lugar de hacerlo sobre toda la distribución?