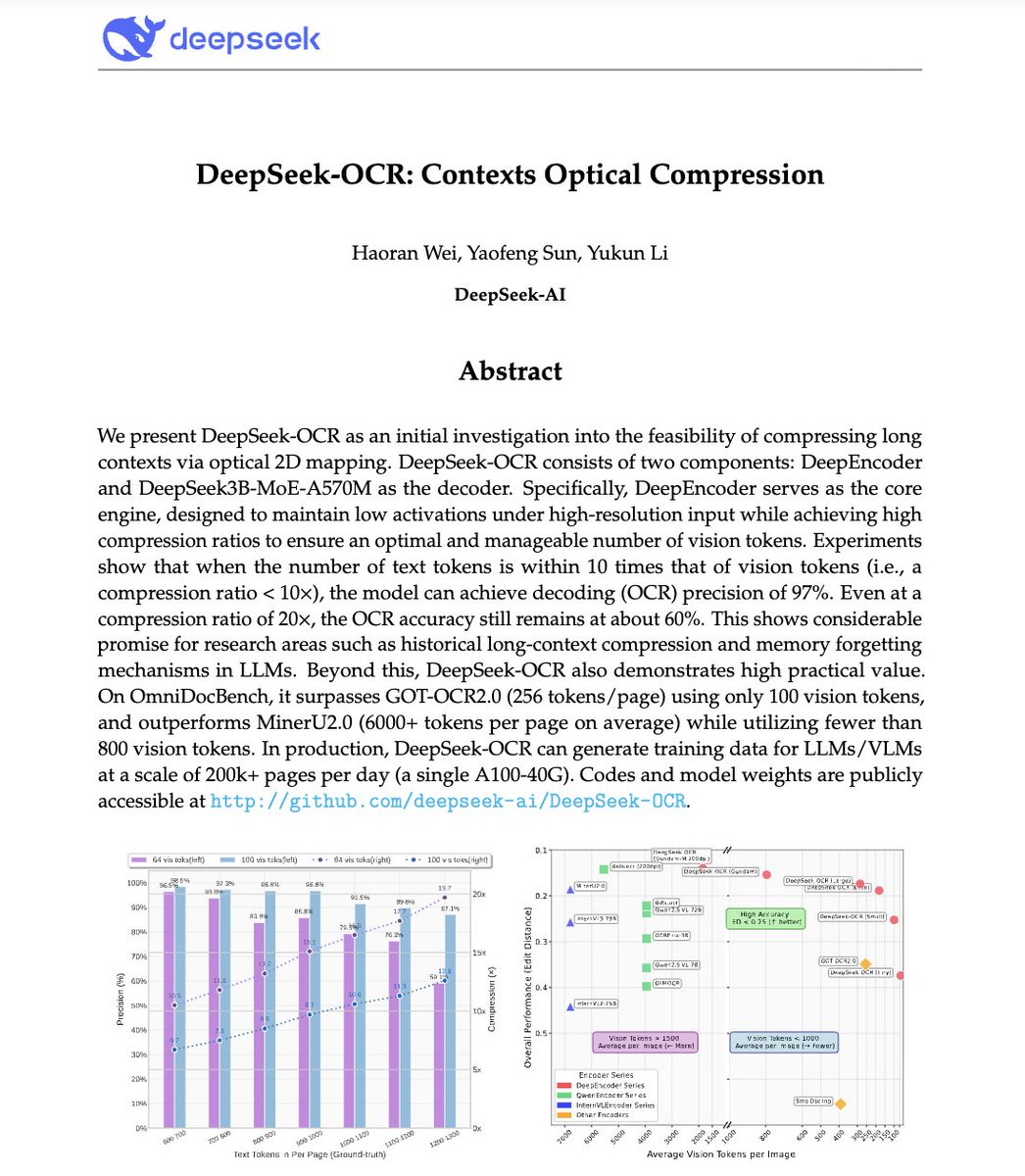
🚨 DeepSeek acaba de hacer algo salvaje. Construyeron un sistema OCR que comprime texto largo en tokens de visión, convirtiendo literalmente los párrafos en píxeles. Su modelo, DeepSeek-OCR, alcanza una precisión de decodificación del 97 % con una compresión de 10× y mantiene una precisión del 60 % incluso con una compresión de 20×. Esto significa que una imagen puede representar documentos completos utilizando una fracción de los tokens que necesitaría un LLM. ¿Aún más loco? Supera a GOT-OCR 2.0 y MinerU 2.0, ya que usa hasta 60 veces menos tokens y puede procesar más de 200 000 páginas al día con un solo A100. Esto podría resolver uno de los mayores problemas de la IA: la ineficiencia en el contexto largo. En lugar de pagar más por secuencias más largas, las modelos pronto podrían ver el texto en lugar de leerlo. El futuro de la compresión de contexto podría no ser textual en absoluto. Podría ser óptico 👁️ github. es/deepseek-ai/DeepSeek-OCR
1. Compresión de visión y texto: la idea central Los LLM tienen dificultades con los documentos largos porque el uso de tokens aumenta cuadráticamente con la longitud. DeepSeek-OCR cambia eso: en lugar de leer texto, codifica documentos completos como tokens de visión, cada token representa una pieza comprimida de información visual. Resultado: puedes incluir 10 páginas de texto en el mismo presupuesto de tokens que se necesita para procesar 1 página en GPT-4.

2. DeepEncoder: el compresor óptico Conozca la estrella: DeepEncoder. Utiliza dos redes principales, SAM (para percepción) y CLIP (para visión global), unidas por un compresor convolucional de 16×. Esto le permite mantener una comprensión de alta resolución sin explotar la memoria de activación. El codificador convierte miles de parches de imagen en unos cientos de tokens de visión compactos.

3. Modo “Gundam” de resolución múltiple Los documentos varían: facturas ≠ planos ≠ periódicos. Para manejar esto, DeepSeek-OCR admite múltiples modos de resolución: Tiny, Small, Base, Large y Gundam. El modo Gundam combina mosaicos locales + una vista global que escala de 512×512 a 1280×1280 de manera eficiente. Un modelo, múltiples resoluciones, sin reentrenamiento.

4. Motor de datos OCR 1.0 a 2.0 No solo se entrenaron con escaneos de texto. Los datos de DeepSeek-OCR incluyen: • Más de 30 millones de páginas PDF en 100 idiomas • 10 millones de muestras de OCR de escenas naturales • 10 millones de gráficos + 5 millones de fórmulas químicas + 1 millón de problemas de geometría No se trata solo de leer, sino de analizar diagramas, ecuaciones y diseños científicos.

5. Este no es “simplemente otro OCR”. Es una prueba de concepto para la compresión de contexto. Si el texto se puede representar visualmente con 10 veces menos tokens, los LLM podrían usar la misma idea para la memoria a largo plazo y el razonamiento eficiente. Imagine que GPT-5 procesa un documento de 1 millón de tokens como un mapa de imagen de 100 000 tokens.

Deja de perder horas escribiendo indicaciones → Más de 10 000 indicaciones listas para usar → Crea el tuyo en segundos → Acceso de por vida. Pago úngodofprompt.ai/pricing 👇