¡Emocionado por lanzar un nuevo repositorio: nanochat! (Es uno de los más desquiciados que he escrito). A diferencia de mi repositorio anterior, nanoGPT, que solo cubría el preentrenamiento, nanochat es un pipeline de entrenamiento/inferencia mínimo, completo y desde cero, de un clon simple de ChatGPT en un único código base con mínimas dependencias. Inicias una GPU en la nube, ejecutas un script y en tan solo 4 horas puedes hablar con tu propio LLM en una interfaz web similar a ChatGPT. Ocupa unas 8000 líneas de código, en mi opinión, bastante limpio, para: - Entrenar el tokenizador con una nueva implementación de Rust - Preentrenar un LLM de Transformer en FineWeb, evaluar la puntuación CORE mediante diversas métricas - Entrenar a mitad de camino con conversaciones de asistente de usuario de SmolTalk, preguntas de opción múltiple y uso de herramientas. - SFT, evaluar el modelo de chat en preguntas de opción múltiple sobre conocimiento del mundo (ARC-E/C, MMLU), matemáticas (GSM8K), código (HumanEval). - Recuperar el modelo opcionalmente en GSM8K con "GRPO". - Inferencia eficiente del modelo en un motor con caché KV, precarga/decodificación sencilla, uso de herramientas (intérprete de Python en un entorno de pruebas ligero), comunicación con él mediante CLI o una interfaz web similar a ChatGPT. - Escribir un único informe de Markdown, resumiendo y gamificando todo. Incluso por tan solo ~$100 (aproximadamente 4 horas en un nodo 8XH100), se puede entrenar un pequeño clon de ChatGPT con el que se puede hablar, escribir historias/poemas y responder preguntas sencillas. Aproximadamente ~12 horas superan la métrica principal de GPT-2. A medida que se escala hacia ~$1000 (~41,6 horas de entrenamiento), se vuelve rápidamente mucho más coherente y puede resolver problemas matemáticos/de código sencillos, además de realizar exámenes de opción múltiple. Por ejemplo, un modelo de profundidad 30 entrenado durante 24 horas (esto equivale aproximadamente a los FLOP de GPT-3 Small 125M y a una milésima de GPT-3) alcanza los 40 segundos en MMLU, los 70 segundos en ARC-Easy, los 20 segundos en GSM8K, etc. Mi objetivo es integrar toda la pila de base sólida en un repositorio cohesivo, minimalista, legible, hackeable y con máximas posibilidades de bifurcación. nanochat será el proyecto final de LLM101n (que aún está en desarrollo). Creo que también tiene potencial para convertirse en una herramienta de investigación o un punto de referencia, similar a nanoGPT. No está terminado, ajustado ni optimizado (de hecho, creo que aún queda mucho por hacer), pero creo que su estructura general es lo suficientemente buena como para subirlo a GitHub, donde se pueden mejorar todas sus partes. El enlace al repositorio y una guía detallada del speedrun de nanochat están en la respuesta.

Repositorio dgithub.com/karpathy/nanoc…Cpm3Dc44rY Guía técnica mucho más detallada: httpgithub.com/karpathy/nanoc…mplo de conversación con el nanochat de 4 horas y $100 en la interfaz web. Es... entretenido :) Los modelos más grandes (por ejemplo, una profundidad de 26 en 12 horas o una profundidad de 30 en 24 horas) se vuelven más coherentes rápidamente.

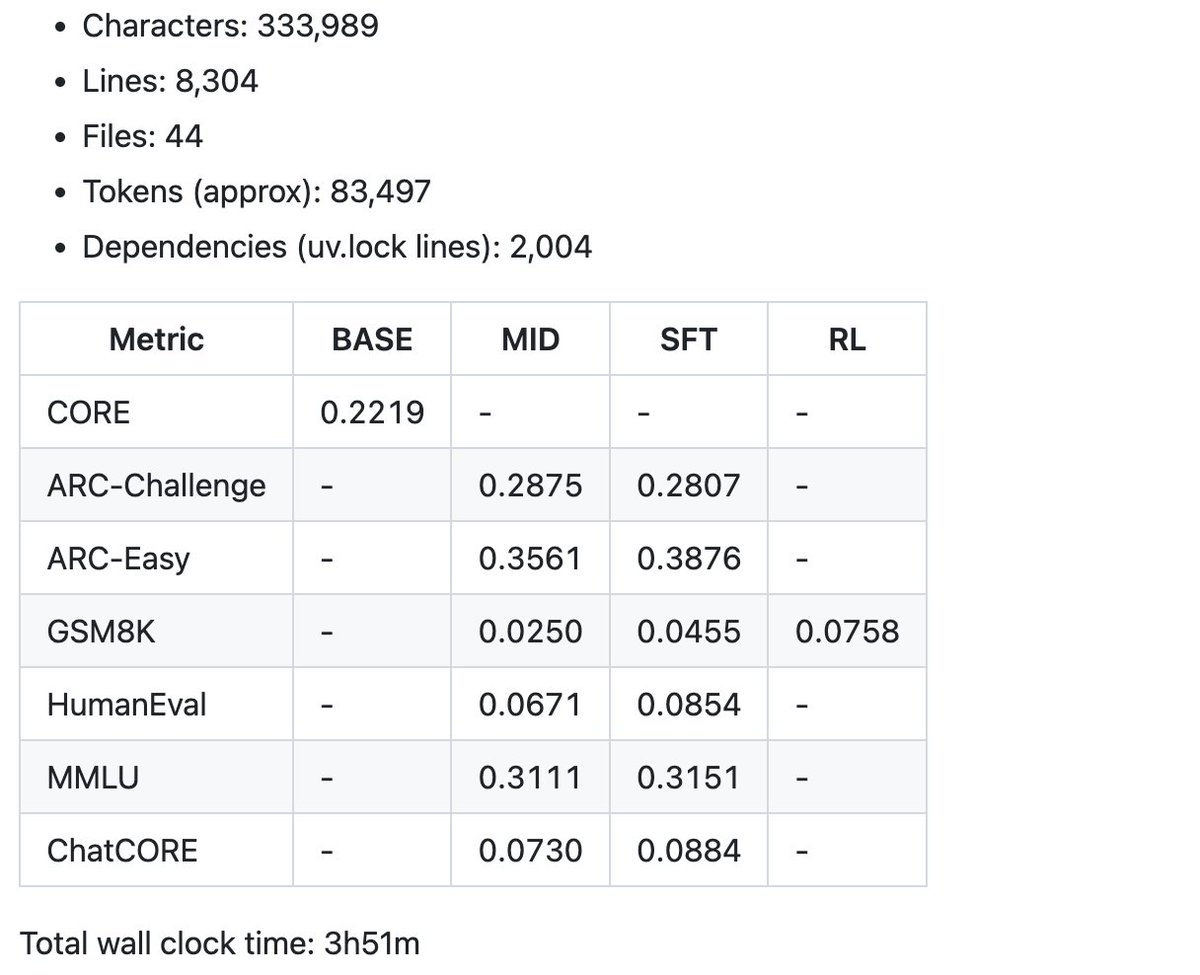
Y un ejemplo de algunas de las métricas resumidas del speedrun de $100 en el informe para empezar. El código base actual tiene poco más de 8000 líneas, pero intenté mantenerlo limpio y bien comentado. Ahora viene la parte divertida: el ajuste y el ascenso.